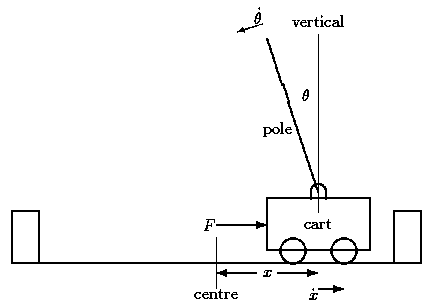
Figure 3.1: The pole and cart, or inverted pendulum
| ©1990, 1995 | General contents |
| Chapter 2 | Chapter 4 |
The review of literature repeatedly revealed what seemed like a lacuna, blocking the way to integrating formalisms and theories with vital practical considerations and observations about the realities of complex tasks. This focused around the question of representation, and it was not at all clear from the literature how to proceed, if not all the way to bridging the gap, at least to surveying and laying some of the necessary foundations for the bridgework.
The studies reported in this chapter were not done as a consequence of the literature findings, but rather served to complement them. These studies were not only investigations of their own branches of literature, revealing similar problems to the main literature, in different contexts. They were also investigations into the practical aspects of the subjects, revealing practical as well as theoretical difficulties.
As such, these studies were very important in beginning to define areas of experimental research which might be more fruitful than others.
Collision avoidance between merchant ships at sea was originally chosen, by those who instigated the research, as an exemplar area of study, for many good reasons. Some of these reasons will be explained in this section. Because it is a good representative task, it also shows the problems of representation clearly, and these will be discussed next. Collision avoidance is described here in some detail in order to get an appreciation of the kind of problems faced when attempting to study a real-life, complex task. These considerations are a significant part of the whole work, despite the fact that there were too many problems standing in the way of research directly on the subject. These obstacles are also described here.
Collision avoidance is a good example of the kind of system, and task, described in the introduction (§1.2). Ships come into view, either visually or on radar, at unplanned times, and have to be dealt with in real-time, no matter what else is happening. Ships are expensive, and a great deal of effort is put into allocating blame for collisions, so that the cost of damages can be apportioned as fairly as possible. A nautical disaster can cost many lives. There can be a large amount of information to be dealt with, though the task can also be uneventful for long stretches. The amount of information that needs to be dealt with depends firstly on what the situation is: in the middle of the ocean, not much happens, whereas in busy shipping lanes near the coast, there are more vessels to keep a look-out for, and more work with the chart keeping a track of the ship's position. The amount of information that needs to be dealt with depends secondly on the kind of ship and the number of people on duty at once. The historical trend is for fewer people and more automation, away from the style of operation associated with navies [60], towards the ‘one man bridge’, where the automatic systems have interfaces within the control of the ‘conning officer’.
Relating to the categories of §1.3, collision avoidance is clearly a dynamic control task, rather than a problem-solving task. Let us take the question of complexity firstly in terms of Woods' categories [145], §1.3.2 above. There is dynamism, though the time constants involved are of the order of minutes rather than seconds—a property shared with nuclear power plants and other process industries. The task can have strong interconnections, particularly when more than one ship presents a potential threat, but also because the different tasks that make up watchkeeping impinge on each other. There is uncertainty, in that it is never certain what actions other ships will take. And there is risk: this is not only the risk of collision (and grounding), but sometimes also the commercial risk of missing deadlines. So collision avoidance would count as fairly complex according to Woods, though perhaps not as complex as nuclear power plant control.
Collision avoidance also has a clear involvement of regulations (the collision regulations [61]), and multiple tasks. Observation of cadets in a high-fidelity night-time training simulator showed, perhaps even more clearly than observing experienced mariners would have done, how there were different elements to the task. (The author spent a week observing cadets in the ship simulator at Glasgow College of Nautical Studies.) As well as giving orders for desired heading, engine speed, and occasionally rudder angle, the watchkeeping officer has to take at least supervisory responsibility for maintenance of the chart and log; for lookout, both visually and by radar (which often involves calculations on the radar screen); for communication with other vessels, pilots and port authorities (including responding to distress calls); for looking after the cargo; and for managing the other people involved in the control and maintenance of the ship, including making sure that people are awake, doing what they should be doing, organising relief or time off vital duties, etc. This kind of human multi-tasking is common in the kind of complex tasks that we are considering in this study.
The present author's definition of complexity (§1.3.2) is in terms of the variety of possible strategies, and by implication (now that we have discussed representation) the variety of possible representations of the task. This is particularly interesting for collision avoidance, as this variety can be approached in more than one documented way.
Around 1970 a number of articles appeared in the Journal of the Royal Institute of Navigation concerned with a possible revision of the collision regulations (see, e.g., the discussion, [116]). Much of the writing focused around the question of whether the existing basis of the rules was satisfactory. The existing rules are based around the concept of right-of-way. In most situations involving the risk of collision, they say that one vessel has to give way, and the other vessel has to ‘stand on’ (i.e., maintain course and speed), to avoid the possibility that any action taken by the stand-on vessel might counteract an action by the give-way vessel. The alternative is to have a system whereby both vessels are expected to manoeuvre, but in such a specified way that their actions add to each other's effect, rather than cancelling it. Cockcroft [25] gives the diagram of manoeuvres that was generally favoured at that time. This discussion establishes the point that opinions differ about the best strategy to adopt as a general rule, and about the concepts that would underlie that strategy.
Although Curtis [29] did not set out to show differences between individuals, his simulator experiments show a great deal of variation between the actions of different individuals presented with an identical experimental arrangement. Since his object was to determine reaction times, Curtis did not publish the reasons the mariners gave for their actions, but he reproduces in diagrammatic form the tracks followed by the 30 individuals. These are remarkably varied. Looking at the diagrams, it is difficult to believe that the mariners were all following the same strategy.
At both Liverpool Polytechnic and Plymouth Polytechnic, there was recent work on collision avoidance advice systems. In making a system capable of giving reliable advice, the task has to be given an explicit logical structure, and the obvious way to do this is on the basis of rules. To make rules, one has to have a representation language that provides the primitives in terms of which the rules will be written. Investigating some finer points of these proposed systems gives some insight into the problems with representing the collision avoidance task.
This takes input from an advanced radar system, in the form of headings and speeds of ships detected by the radar. These raw data are then interpreted into categories that are used and understandable by mariners, and of the type also used in the Collision Regulations, such as “crossing from starboard to port, passing ahead”. In the Liverpool system, there are 32 valid combinations of this kind of descriptor, and five other descriptors dealing with other information relevant to the collision regulations and the likely inferences of an officer of the watch. 14 possible collision avoidance actions are identified, the last of which is a default category of “emergency” when none of the other 13 actions are appropriate. The derivation of the best appropriate collision avoidance action from the descriptors is governed by rules and procedures internal to the advice system. The rules were derived from expert mariners, who did not always agree, while the procedures to find the solution consisted largely of orderings and heuristics to guide the search for a reasonable solution, avoiding the necessity of trying out every possible manoeuvre with every target. After generating a likely action, that action is tested against all the targets, to ensure that no advice given could lead to a collision or near collision.
Liverpool's system is geared to providing advice to the officer on the bridge, and the complete calculation is reworked every 15 seconds. If advice has been given, but not taken, it may become appropriate to offer different advice. This is what is done.
The system represents consensus opinions on reasonable actions to take in the situations as described. However, a number of questions may be raised about the representation used. Firstly, the descriptors chosen were derived from the Collision Regulations, plus a consensus of mariners. If the regulations changed, this would be likely to invalidate the descriptors, not just the rules: this might be acceptable on the basis that everyone should be working within the same regulations. But what if certain mariners had other descriptors that they used, consciously or not, in their collision avoidance strategy? This would imply that the Liverpool system might give advice that was inconsistent according to some mariners' views. The research issue here would be to establish that mariner's descriptors were fully covered by the system's descriptors. Secondly, some mariners might characterise the range of actions available to them differently from the system. Again, the research called for here would be to investigate the actual range of actions that are used, and to ensure that all actions taken by mariners are given in the system. However, this would still be a problem, in that the system might give advice to a mariner to take an action that is not within that mariner's normal repertoire.
The possible use of situation descriptors other than the ones recognised by the system raises a yet more troublesome point: what if some of the descriptors used by mariners are not available to a system electronically? The lights that a target vessel shows are an obvious example. But more worrying still, how about the feeling that a watchkeeping officer gets, that the crew of a certain vessel are not going to comply with the rules?
Another problem for advice systems of this kind comes from the varying usefulness of such a system in situations where the user has different amounts of experience. Among collision avoidance situations, some occur more frequently than others. Generally, it would be reasonable to expect that in the more commonly occurring situations, there would be more knowledge and opinion available in the nautical community about good ways of responding to such situations. Equally, any particular mariner is more likely to have a worked-out strategy for dealing with these cases. These are the cases where the advice system will be at its most reliable, but also the cases where it will least be needed. On the other hand, in situations that occur only infrequently, watchkeeping officers are likely to still be at the learning stage, trying out different possible actions, and learning from experience. Following advice from the system would at least work most of the time, although this will not allow an officer to learn from different possible approaches, and develop a personal style. But it is in just the least familiar situations that the system gives up, leaving the mariner with an ‘emergency’ that is at best ill prepared for, and even less prepared for if, due to the availability of the advice system, a personal strategy has not been developed.
Research at Plymouth has had automation more in mind, and perhaps for this reason the published paper has different priorities from Liverpool's publications, and does not describe the decision process in detail. The principles of the system design are clearly similar, with a rule-based approach being used. However, even at this relatively early stage of development, it can be seen that the representation used is not identical to that used by Liverpool. For example, they use different ways of calculating the time at which an avoidance manoeuvre should take place. This reflects debate in the Journal of Navigation about what criteria to use for modelling mariners taking avoiding action (e.g. [30]). As we consider levels of detail finer than given in the publications, it would be even more likely that differences would emerge, simply because of the difficulty of unambiguously describing a correct approach to the collision avoidance task.
An authority has suggested that ship's masters often feel the need to imprint their own personality on the job, and that all certificated officers took pride in their ability to “interpret a situation”, and that the heuristic knowledge gained from experience “is more valuable to them than their slavish knowledge of the Collision Regulations” [48]. This reinforces the idea that different watchkeeping officers have different personal styles, and therefore probably different representations of the task.
There is also hearsay about the usage of modern electronic aids to navigation. It is thought that there are ships where the officers do not know enough about their radar equipment to make proper use of it. This applies particularly to the more modern equipment such as ARPA (Automatic Radar Plotting Aid), which provides the facility to predict, and display graphically, where vessels will be at a future time, assuming they hold their course and speed. In many collisions in fog, there is a suspicion that at least one of the parties was not using their equipment properly [19, p.163]. On the other hand, some channel ferry operators are thought [48] to base their (very effective) collision avoidance strategies around a modern electronic aid that shows danger areas to be avoided round other ships (the Sperry PAD system).
It would seem that strategies, and representations, are built up in the context of what information is available, and people may not be very good at adjusting their old strategy, built up over many years, on the introduction of new equipment.
Despite the wealth of interest in a study of maritime collision avoidance, there were obstacles preventing its direct study. The first of these was the inability to secure machine-readable data.
Real ships would be the ideal place to secure data on collision avoidance. However, they do not have automatic recorders, such as the ‘black box’ devices on aircraft that are analysed after crashes, etc. To install such a device on an operational ship would be technically very complex, and it is doubtful whether ship owners would be happy having their radar equipment interfered with, and doubtful whether watchkeeping officers would be happy having all their actions recorded.
Despite the fact that nautical simulators are driven by computer, it is difficult to get machine-readable data from them. The computer architecture tends to be specialised, with little or no provision for data links to other systems conforming to any standard. Only one such link in Britain was known to the author, at the College of Maritime Studies, Warsash. This connection has been used in the study of collision avoidance behaviour [49], but the simulator is heavily used in routine training, and not readily available to outsiders for extensive experiments.
Even if the problems with data were solved, there would be still further problems in using lifelike maritime collision avoidance as an object of study.
The multi-task nature of collision avoidance has been described above, §3.1.1. In current simulator training (as observed by the author), the tasks that do not normally have a mechanical or electronic interface are simulated by having a very skilled simulator operator, who takes on the role of all the agents not immediately present, such as the engineers, pilots, port authorities, other ships, etc. In training simulators, with cadets, the other unformalised aspect of the task is the interaction of the officer of the watch with the other people on the ship's bridge. To include all this information, or to leave it out, both have problems. Including it would mean recording by hand and formalising data that it is not clear how to formalise. A realistic situation would result, but the complexity of this full realism would make the task more complex, and lengthy to learn. Lifelike collision avoidance involves long stretches of time at the task, and this too would cause problems for experimentation. It is not easy to formalise the time relationships of events which either have long-term consequences or need long-term planning (of the order of hours). On the other hand, leaving out this kind of information would make the task unrealistically easy, perhaps so easy that there would be little complexity to the task, and a logical analysis would suffice. That would mean that it would be an unsuitable object of study here. A one-man bridge simulator would be another alternative, eliminating the social side of the task, but such simulators are not widespread, and none was known that would be available.
This difficulty in simulating the collision avoidance task could be traced back to the question of whether collision avoidance actually constitutes a separate task of navigation. Clearly one can think of it as a separate aspect of the task, but perhaps it only acquires its particular character in the context of the wider task of navigation. Although it is quite easy to set up exercises on collision avoidance in ship simulators, it is notable that there are in general no such separate exercises in the use of ship simulators for routine training. If one cannot helpfully think of collision avoidance as a separate task, then analysis of it would only make sense if one analysed the task of navigation as a whole, which, as has been pointed out above (§3.1.1), has many aspects, and some of those aspects might frustrate attempts at formalisation and modelling (discussed below, §8.2.1).
In the attempt to study human control of complex systems, studying collision avoidance in a realistic situation was a direct approach: but since that proved to have too many difficulties, a more roundabout approach was worthy of consideration, going via studying the control of a simpler dynamic system. The idea would be to start off modelling how people perform a task that is relatively easy to specify, and then gradually to extend the model to cover the control of more and more complex systems, until one is able to model realistic complex tasks. The realisation that there are no successful models even of human skills acquired in childhood, such as bicycle-riding, suggests that the approach via simpler skills is at least challenging.
Figure 3.1: The pole and cart, or inverted pendulum
One of the simplest dynamic control problems to be studied is that of the inverted pendulum, or pole-and-cart system (see Figure 3.1). In this system, a rigid pole is connected by a hinge at its base, to a cart which is constrained to move along a linear horizontal track. A force is applied to this cart: if appropriate forces are applied in a timely fashion, the pole can be kept from falling over, and the cart kept from wandering too far away from its starting position. Typical values used in the simulation are:
In some ways, the task of pole-balancing is at the opposite end of the spectrum to collision avoidance. As we have discussed above, collision avoidance has much complexity, and consequently there are problems in research methodology. A real pole-and-cart system may have relatively few problems, depending on the details of the physical system: in an idealised version, simulated on a computer, there are no unknown influences on the system. If machine learning is being studied, and no humans are involved, the research methodology is relatively straightforward.
In amongst the early literature on controlling the pole-and-cart system, there are mentions of involving humans, and possibly learning a skill from a combination of human input and machine learning techniques. The objects of this section are to examine this literature, considering how it reflects on the issue of representation, and to consider the implications for the study of complex human control tasks.
Donaldson [31] uses the pole-and-cart apparatus essentially as described above, to demonstrate a technique of learning which he terms “error decorrelation”. This is an early suggestion of a way in which one might learn from a human how to perform some skill. The task in this case is to give as output a suitable value for the force to be applied to the cart. This output is constructed by taking a number of measured system variables (which we can think of as defining the ‘situation’) and multiplying these by a set of coefficients. If there is more than one output variable, the same arrangement would be be replicated. The system learns from example: that is, an ‘expert’ output is given from some other source, and the learning mechanism attempts to adjust the coefficients so that it matches the expert output as closely as possible. If the expert control signal correlates at all with any of the measured variables, the response of the learning system will become closer to the expert output.
We see here the dependency of learning on an adequate representation of the system. If the expert signal is not correlated to something that is measured, Donaldson's learning process will fail to learn.
Eastwood [34] makes the point that in order to construct a control engineering solution to a problem it is necessary to “identify as many as possible of the contributory variables and to express their interrelationships in terms of mathematical models which can be simulated on the computer”. Using control theory, he derives a method of controlling the pole-and-cart system that we have described above. Eastwood gives results in the form of graphs plotting the behaviour of simulated, and real, pole-and-cart systems. For the idealised simulation, the control, and recovery from disturbances, is very quick, efficient and smooth. Applying the same control to a real pole and cart, the resultant motion is more erratic, though still well controlled. No mathematical model of a real system can ever be perfect, and the results from the real system illustrate the effect of the imperfections in modelling.
Human control of such a system differs in appearance from the control engineering solution. In pole-balancing, human physical control is not based on explicit mathematical analysis, and hence it does not suffer from the need to have detailed mechanical descriptions of things before being able to control them. For systems that are able to be thoroughly analysed, human control is liable to be less accurate, smooth, or efficient than theoretically-based control, but for systems that have not been thoroughly analysed, humans are still able to learn control where theoretical solutions are not yet possible.
Control theory is rooted in continuous algebra, and is quantitative rather than qualitative. Using qualitative control techniques [24] results in a response that at least superficially appears to be more like human control and less like that based on control engineering. So it seems reasonable to assume that the investigation of qualitative techniques would lead us closer to an understanding of human control.
An early qualitative approach to pole-balancing is given by Widrow & Smith [141]. Their approach has some similarities to that of Donaldson, but is based on a discrete, rather than continuous, representation of the problem. They also introduce ‘bang-bang’ control, in keeping with their qualitative approach. However, they are much more concerned with demonstrating that their system can learn something, than with the relationship between this and human skill. This paper is one of the prototypes of the research which is now termed ‘connectionist’ or to do with ‘neural nets’.
Michie & Chambers [80] take a much more explicit approach to learning to control the pole-and-cart system, and the learning is not from an expert, but purely from the experience of failure, which in human terms is a much harder learning problem. Their basic strategy is to divide up the state space of the problem into ‘boxes’ (hence the algorithm name), which are defined by thresholds—particular values of each dimension of the state space. One can imagine the boxes as box-shaped regions of state space.
‘In’ each box, a separate learning process is going on. The data which is passed to each box includes what time, or how many moves, elapsed between that box's decision and ultimate failure. So, by a process whose details do not concern us here, each box learns what is the best decision to take. When each box has learned a good decision, the decisions of all the boxes put together constitute a strategy for the task as a whole.
Fundamentally important to the ability to learn well is the selection of the state space dimensions, and the choice of thresholds to divide the state space up into boxes. Each box is a region of state space that is treated as uniform for the purposes of the learning algorithm. If a box includes regions where a good strategy would recommend different actions, then this may compromise the ability of BOXES to learn any effective strategy at all. Attempting to avoid this problem by having very many very small boxes leads to long computation times, and strategies which are even less homogeneous and comprehensible.
Given the importance of the choice of dimensions and thresholds, one would expect the authors to discuss it in detail. In fact, they accept the problem dimensions as they would be defined by engineers, without comment. One could at least say that the dimensions given (x, x dot, theta and theta dot) are able to describe any possible state of the idealised system. Of the thresholds, they say very little. It seems as though the values were derived by a process of trial and error, guided by human intuition, and therefore difficult to document. The choice of dimensions and thresholds is clearly a problem area, and this corresponds to our problem of representation, as already discussed.
Chambers & Michie [22] discuss possible human-machine cooperation on the task of learning to balance the pole-and-cart. It must be pointed out that their objective was not to replicate a human skill by using machine learning, but rather to short-cut the process of learning, which in Michie & Chambers is entirely by experience of failure.
Chambers & Michie envisage three kinds of cooperative learning. The first is where the BOXES algorithm just accepts the decisions from the human, without effecting any decisions itself. The second is where there is provision for the human not to give a decision, and to leave it up to the algorithm, so that the decision-making would be shared. In the third case, some criterion would govern whether the algorithm had enough confidence in its decision to override any decision that the human might take.
The authors point out that BOXES can complement a human by providing consistency where a human might be inconsistent. However, whether this is an advantage depends on whether the representation is a good one. If the thresholds are badly placed, or the dimensions wrong, ‘inconsistency’ within a bad box may be the optimal strategy, and in this case BOXES would be reducing appropriate ‘requisite variety’ that the human had. On the other hand, if we knew what dimensions and thresholds were used by the human, then enforcing consistency might well improve performance, and BOXES would be truly cooperating with the human. There is, however, no discussion in this paper about what a human representation might be, or how to discover one.
More recent work on the pole-and-cart system adds little to the originals, from the point of view of the present study. Makarovic [75] derives qualitative control rules by consideration of the physical dynamics, together with many simplifying assumptions. Bratko [17] derives control rules from qualitative modelling. Sammut [118] extends the original BOXES work by performing rule-induction on the decisions generated by BOXES rules, to get a humanly comprehensible and concise set of rules not unlike Makarovic's. Between the time of consideration and the time of writing, researchers at the Turing Institute have done some work on the human control of a pole-and-cart system [79]. They do not derive any new representations for human control.
Little work has been done on the human side of pole-balancing. No empirical tests of representations have been made, to assess how closely they correspond to human representations. No-one has claimed to have discovered a specifically human representation of pole-balancing.
Makarovic's rules [75] are in fact for a double pole system, where a second pole is hinged to the top of the lower pole. For the sake of simplicity, we here give the form of the rule for balancing one pole, which comes from assuming that the top pole is perfectly balanced at all times. The notation is also simplified to accord with that already introduced.
IF theta dot = big positive THEN Push Left
IF theta dot = big negative THEN Push Right
IF theta dot = small
THEN IF theta = big positive THEN Push Left
IF theta = big negative THEN Push Right
IF theta = small
THEN IF x dot = big positive THEN Push Right
IF x dot = big negative THEN Push Left
IF x dot = small
THEN IF x = positive THEN Push Right
IF x = negative THEN Push Left
The “big positive”, “big negative” and “small” values are
exclusive exhaustive qualitative ranges.
Although this rule is given in terms of the four basic physical quantities, its derivation used the idea of desired reference values for the quantities, justified in terms of control concepts. The present author also used this kind of approach, but justified in terms of human understandability, in devising an alternative representation for the pole-and-cart system. This was attempting both to enable a physical pole-and-cart apparatus (functioning at the time in the Turing Institute) to balance for longer than was being achieved by other means, and also to try out a representation that had more human flavour to it. The principle of this representation is to calculate desired values of the various quantities, and to represent explicitly the deviations of the actual values from the desired values, which would in turn affect the desired values of other quantities.
In the pole-balancing task, we may fix a particular position on the track as the place where we wish the cart to be. The difference between the actual position and this desired position—the distance discrepancy—determines what we wish the velocity to be. The connection between distance discrepancy and desired velocity may be done in two ways: either quantitatively, for example by making the desired velocity a negative factor times the distance discrepancy; or qualitatively, by dividing up the range of distance discrepancies into a small number of sub-ranges, and for each of these sub-ranges, assigning a particular value to the desired velocity. We may continue in the same fashion, qualitative or quantitative. Comparing the desired velocity of the cart to the actual velocity, we obtain a velocity discrepancy, and a desired acceleration of the cart can be fixed as a simple function of the velocity discrepancy. The desired acceleration may then be converted directly into a desired pole angle, based on the fact that the pole would be in unstable equilibrium at a particular angle, depending on the acceleration of the cart. Comparing the desired angle with the actual angle can give us a desired angular velocity, analogously with position and speed. Finally, comparing the desired angular velocity with the actual, we can derive a control decision, whether to apply the force to the right or to the left.
Implementing this strategy requires the setting of the functions which derive a desired value from a previously measured discrepancy. In practice, all except the last function were linear relationships, with constants that had the nature of time constants in exponential decay. It was discovered, by intuitively-led trial and error, that good results were obtained by setting what was effectively a short time constant for the last part of the decision (going from the angular velocity to the force), with progressively longer time constants, the longest governing the connection between discrepant position and desired velocity. This strategy was tried on a simulated pole-and-cart, producing control with apparently no time limit. The quantitative version led to an apparently static system on the graphic display, while the qualitative version led to small oscillations around the desired position. The quantitative version, suitably adapted to the physical apparatus, produced runs balancing for longer than had been achieved using Makarovic's rules implemented on the same apparatus (this was of the order of a minute or two).
It cannot be claimed that this was in any way a model of human control of the pole-and-cart, because no comparison was attempted. However, it does show that using a different representation of the problem can lead to solutions that are at least as good, and at least as comprehensible, as the representations already tried.
The problems in representing human control are more obvious than the problems in representing expert knowledge of the type used commonly in expert systems. In medical diagnosis, for example, the decision classes are the different possible diseases, and at least in many cases, these diseases fall into well-defined natural kinds. There is no disease ‘half-way’ between mumps and measles. Also, as a consequence, much of the knowledge is able to be written down, and discussed, and the general kinds of symptoms that are relevant for diagnosis are reasonably well-known. It follows that representation of the problem is relatively easy, even though the rules for diagnosis may be intricate and uncertain, and probabilistic rather than definite. It is in this context that the classic study of soy-bean diagnosis [77] shows such success for machine learning. Because representation in this field is so clear-cut, Michalski & Chilausky did not report any difficulty, or even alternatives, in the choice of representational primitives for soy-bean diagnosis.
Many other papers in machine learning, up to the present, have considered methods of learning classifications based on some predefined set of attributes. Some recent algorithms extend the representation language, by introducing new predicates (e.g. [86]), and other recent work [154] considers the effect of differently aligning the axes of the problem space, to allow more effective rule-induction. Indeed, the idea of change of representation is now established as a topic within machine learning (see, e.g., [121, 137, 149]). Nevertheless these new techniques generally rely on the assumption that there is some underlying fundamental adequate description language known for the problem, which implies that the problem of change of representation could be seen as a search through a large but bounded space of possible representations.
This approach does not fit well onto discovering human representations. Our set of possible concepts is at least exceedingly large, if not actually unbounded, and there are no known laws restricting human ingenuity and imagination in representing problems or tasks in various ways. We certainly do not yet know what the principles governing human representations might be, and so we cannot predict in detail how a human might represent a problem, or what the possible range of human representations is.
Unassisted machine learning, purely from experience, is still a long way from being able to deal with complex tasks. To that extent, it as yet fails to give us a model of human learning about complex systems. It neither ties in with, nor validates, the study of mental models used in training, discussed above (§2.1.6). Nor is there much current concern with the structure of human representations. In a way, this is surprising, because the concept of the ‘human window’ into intelligent systems has been discussed for some time [81]. It would seem obvious to the present author, that if intelligent systems are to have an effective human window, much more must be learnt about human representations, so that human and computer can share a language in which to communicate.
Certainly, the mere fact that a representation is qualitative rather than quantitative does not mean that it is human-like. Machine learning, of itself, does not reveal human representations. The machine learning community is aware of the centrality of representation, but offers no systematic approach to discovering representations, either of human performance, or of unstudied applications, where also there is no known underlying representation out of which to select and build a new one.
Learning about human control rules depends on having a satisfactory representation language in which to describe the rules, and because we do not have any techniques for discovering that representation language, machine learning cannot yet provide a good model of human performance at a complex control task.
Further work for machine learning will be dealt with in the appropriate place (§8.3), but this study now continues with experimental approaches to discovering more about human representations and complex task performance.
| Next Chapter 4 | |
| General Contents | Copyright |