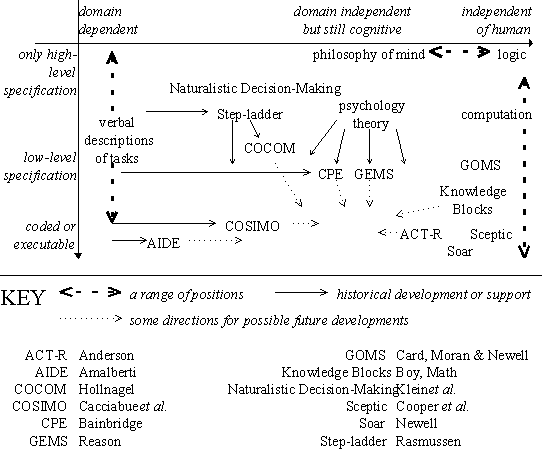
Figure 1: A selection of work on cognition in complex tasks plotted on the dimensions of domain-dependence and level of specification, showing potential developments
| © 1995 11 | Home page | Publications | Paper frame | |
| Bibliographics | authorship | abstract | contents | references |
Simon Grant
(then at)European Commission, Joint Research Centre
Institute for Systems Engineering and Informatics
Ispra (VA), Italy
A cognitive architecture embodies the more general structures and mechanisms out of which could be made a model of individual cognition in a certain situation. The space of models and architectures has a number of dimensions, including: dependence on domain; level of specification; and extent of coverage of different phenomena.
Cognitive architectures can be assessed in terms of their ability to support the construction of models and simulations of cognition and error. ACT-R is an example of a moderately specified architecture, in which one can build such simulation models. There are some features that are important in the study of complex tasks that ACT-R is not well-adapted to modelling: included among these are the modelling of certain types of error. ACT-R does not by itself strongly constrain a model to be psychologically plausible - that is left to the person building the model. The architecture derived from COSIMO is open to extension and improvement in a similar way.
Relevant work towards developing cognitive architectures for modelling cognition and error in complex tasks can include on the one hand generalizing from domain-specific models, based on results from the study of cognition and errors in real complex tasks, and on the other hand hypothesizing more detailed computational mechanisms for the implementation of general error-prone cognitive abilities, which may be pointed out by cognitive psychology. It would appear to be best if these two approaches progressed hand in hand, since they are two sides of the same enterprise.
Complex, dynamic tasks, such as one sees in the fields of process control, power plant control, and especially in the control of vehicles such as modern ships and aircraft, are widely recognised as being prone to human error. Much of this is attributed to errors in the mental, rather than purely physiological processes of the human. In order to classify these errors according to their cause, to assess their likelihood, or to design control and supervisory interfaces that are safer and more tolerant of human errors, workers in the fields of cognitive engineering and related human factors areas (including many of those cited below) have either attempted or suggested the modelling of the human cognitive processes involved in the complex task of controlling the system.
For useful modelling of human cognitive processes to help with such things as interface design, the model has to support prediction of some noticeable effects of an interface. In the case of complex tasks involving complex and expensive technology, where human error contributes significantly to the risks to the system, the model of cognition should ideally predict the human error implications of an interface. Such models of cognitive error could take a number of forms, and be at a number of levels. One of the more ambitious approaches is to further the tradition of COSIMO (Cacciabue et al, 1992) to simulate error-prone cognitive mechanisms (e.g. Reason 1990) that underlie individual human performance, so as to simulate, predict and assess the likelihood of the errors that humans, considered as individuals, are likely to make.
An even more ambitious approach would be to simulate the cognitive processes of the whole human system, including human-human interactions, co-operation, and teamwork. Since it is systems that fail (Woods et al. 1994), modelling the error potential of the whole system is an even more worthy goal, but this paper restricts itself to the better-established field of modelling individual cognition. In any case, a good model of co-operation and group cognition must include some model of individual cognition, so one can see a model of individual cognition as contributing to that further goal.
Building models of sufficient richness and complexity is a difficult enterprise, which can be made easier with the help of tools, techniques, principles, and perhaps development methodology. One could compare building models and simulations to building physical structures, where the term 'architecture' stands, in general, for the knowledge that provides the support at least for the design of usable and buildable structures. By analogy, it seems reasonable to use the term 'cognitive architecture' to refer to a particular set of (conceptual) structures, tools, techniques and methods which can support the design and construction of models of cognition. This definition is far from precise, and since architecture is a key concept for this paper, the meaning of the term needs to be considered in more depth, and the distinctions between architecture, theory, model and simulation need to be examined, particularly along the dimensions of domain-dependence and level of specification.
The next step is to identify what could be developed, and how, into an architecture better adapted for the modelling of human errors in complex tasks. This can be approached from a comparison of the variety of work in the field, and also by detailed study of examples that are close enough to the desired architecture. In this way, directions for the development of cognitive architecture are shown, and on this basis we can appreciate more clearly possible future developments.
Cognitive, in this paper, means to do with human cognition or models of human cognition. There seems little point in extending the term to cover information processing or computation more generally. This would agree with most implicit usage in the literature. On the definition of architecture, on the other hand, authors tend to say only a little. Because the definitions given are short and not entirely clear, a good view of the current usage requires that the crucial passages be represented, as here.
Wright et al. (1995), working in the field of modelling cognition and affect, use the term 'architecture' in a similar way to that introduced above. To them, it means
"a collection of features common to a class of entities. Each instance of an architecture is composed of coexisting, interacting substructures with various capabilities and functional roles. A substructure may also have an architecture. The architecture of a complex system can explain how its capabilities and behaviour arise out of the capabilities, behaviour, relationships and interactions of the components. An architecture can be specified at different levels of detail, e.g. at a high level of abstraction the architecture of a house will not include the occurrence of particular bricks, whereas a more detailed architectural specification would."
Anderson (1993) is one of the foremost current exponents of cognitive architecture. His view is as follows (pp 3-4, emphasis original).
"Cognitive architectures are relatively complete proposals about the structure of human cognition. In this regard, they contrast with theories, which address only an aspect of cognition, such as those involving the distinction between long- and short-term memory. … The term cognitive architecture was brought into psychology by Newell (Bell & Newell 1971). Just as an architect tries to provide a complete specification of a house (for a builder) so a computer or cognitive architect tries to provide a complete specification of a system. There is a certain abstractness in the architect's specification, however, which leaves the concrete realisation to the builder. So, too, there is an abstraction in a cognitive or computer architecture: one does not have to specify the exact neurons in a cognitive architecture, and one does not specify the exact computing elements in a computer architecture."
In this quotation, "relatively complete" can be understood to mean relative to the objectives of the aspects of cognition that are covered by the architecture.
In contrast, Cooper et al. (1995) do not use the term architecture, but instead talk of the methodology of specifying the theory that underlies cognitive modelling. Thus their term 'theory' includes the high-level aspects of architecture as defined by the others. To continue clarification, we now look more deeply into the use of the term in its older sense of physical building, and from that will emerge what cognitive architecture will mean here.
The analogy from cognitive architecture back to the domain of physical construction is complicated by the fact that one does not say, in common English, that a house has "an architecture". One would say that was built in a certain architectural style, tradition, or school, or with certain architectural techniques or features. There are similarities and differences between houses built in the same style, or in different styles. It is this whole style or tradition, along with its materials, tools and techniques, that one could best imagine being called an 'architecture' in a way that would relate to cognitive architecture. An architectural style or tradition one can see as existing as an abstraction from, or the common elements of, a potentially large set of actual or possible houses, and in the same way one could see a cognitive architecture as being an abstraction from many actual or possible cognitive models.
While it would be difficult to describe all the components that make up an architecture, some aspects are easier to appreciate. At a low level, that is to say concerning low-level components, a physical architecture may involve bricks, stone, wood, or concrete. There is a sense in which one could say, 'brick architecture', but of course the number of buildings and structures that would be included in that term would be very large, and the fact of specifying brick as an architecture would not constrain the higher-level design a great deal, though the materials chosen have an effect on the cost, and the ease of construction, since some materials are more suitable for some kinds of structure.
In the analogy, the lowest level of cognitive architecture involves the choice of programming language for implementation. As with buildings, the choice of implementation language may not severely constrain the models built in principle; but in practice it can at least make a considerable difference to the ease of construction and the resources necessary. At this level the choice would also be made between symbolic, neural or hybrid approaches, since in practice what can be achieved by artificial neural nets differs from what can be achieved by symbolic techniques. The most appropriate time for a consideration of this level would appear to be after both the high-level decisions have been made on what the models are intended to do, and the intermediate level decisions about the means of achieving those aims. No more will therefore be said here of this level of architecture.
There are then intermediate levels of architecture. For buildings, one may consider structural components such as arches, beams, slabs, foundations, etc. For cognitive architecture one may consider, as examples, production system architectures, the "blackboard" architecture, or the structures dictated by a knowledge engineering system or expert system shell, a high-level specification language such as Sceptic (Cooper & Farringdon 1993), or an object-oriented approach. This level of specification should ideally follow after an appreciation of the high-level characteristics of the cognitive models, at the point of deciding in general terms what kinds of mechanism would be suitable for their implementation. It is risky to specify a cognitive architecture to this level in advance, because is in generally unclear to what extent such choices constrain the functionality of the end-product models. This level is therefore peripheral to the discussion here.
At a high level of specification, building architecture could include some assumptions about the purposes which the building will serve, and general concepts of the necessary logical structure of the building to fulfil those purposes. An ordinary western European family dwelling house would be expected to have various rooms including living room, bedrooms, kitchen and bathroom; but in other cultures and architectural traditions the purposes of such buildings may be different, and so too their structure. The architectures differ partly because the intended functions differ, partly because of availability of materials, tools and knowledge, and partly due to tradition and fashion.
It is this level of cognitive architecture that is particularly of concern in this paper. What is the purpose of, in this case, cognitive models of error in complex tasks? What can one consider to be the desirable high-level features of an architecture in which such models could be built? This question is particularly challenging considering the development of architecture for which no models currently exist. Rational progress in the field of study should include considering what purposes the models serve and what is required of them, and then attempting to specify an architecture which will make their construction easier.
If a cognitive model is something created with the aid of a cognitive architecture, or if a cognitive architecture is a generalisation from many cognitive models, what is a simulation? There is no clear consensus about the exact definitions of these terms, and this point may also be clarified using the building analogy.
In order to build a building, one must fully specify all the components of the architecture (explicitly or implicitly) and one must take all the decisions that relate to the particular location and purpose of the building. Similar constraints attach to the building of a simulation. The cognitive architecture must be fully specified, and the particulars of the domain must be captured and represented in a form which is usable by the cognitive mechanisms to give a simulation of cognitive performance in the selected task area. The fact that the details must be fully specified is a very valuable constraint. In the words of Cooper et al. (1995),
"computational techniques … lead to precise statements of theory by forcing the detailed specification of all aspects essential to the theory's implementation, including many aspect which might otherwise be overlooked. Computational techniques also allow predictions to be drawn from those theories by simulation.".
Anderson (1993) also stresses that the implementation level is important to the complete specification of cognitive architecture. So the analogy is between the building and the simulation. There is also an analogy to be drawn between the physical plan and the cognitive model. In the cognitive case, it seems that at almost every level, the more one moves towards implementation of a model, the more consequences feed back into improvements and adaptations at the more theoretical level. In the physical case, architects plans often get modified at the time of building, to take into account the unforeseen aspects of the physical construction process.
There are some uses for building plans that are independent of the actual construction of the building. Getting agreement, and permission, to build is one of the functions of plans, and similarly, unimplemented models of cognition can serve useful purposes in allowing a speculative assessment of the potential of a simulation were it to be built. Where little is known about practical implementation details, however, such assessment of the value of a model will be an inexact process.
The idea of a model is thus more general than the idea of a simulation. A running simulation implies a model fully specified in the matters that are being simulated, though the extent of what is simulated varies between simulations. Some models are so simple that they are easily fully specified, and can be implemented simply in the head or on paper. In this case, computational simulations are not needed and the distinction between model and simulation blurs. In the case of cognitive architecture for complex tasks, the models will not be that simple, and simulation remains a very important way of ensuring consistency and completeness in a model.
What is the relationship to the cognitive models and architecture as intended here and 'actual' human cognition? The positions taken by various researchers vary considerably, from Anderson (1993), quoted above, saying that architectures are proposals about the structure of human cognition, to Woods & Roth (1995) stating unequivocally that a cognitive simulation (in particular, their CES) does not constitute a theory of cognition. There is certainly a difference in attitude: one researcher might see divergence between model output and human output to be a disproof of an underlying theory; whereas another researcher might create a model deliberately as a useful approximation, whether or not it was accurate.
Despite great differences in rhetoric and in stated intention, it is difficult to separate the different strands of research on the basis of how they relate to 'real' cognition. None of the theories, models or architectures present themselves as complete with respect to human cognition ('unified' (Newell 1990) does not mean complete). None of the ones discussed here could be complete, because, just to take the most obvious matter (among others), they do not attempt to model the neurophysiological architecture of the brain, and so will miss any effects that are only manifest at that level.
In the end, that kind of issue is peripheral to this paper. What matters for modelling error is that the simulations must replicate, as well as possible, the patterns, attributes and circumstances of human error. Realism in this sense is important for practical reasons, whereas at the level of architecture realism is both less important and very difficult to evaluate. There is nothing to say that an artificial architecture cannot support a realistic simulation. If there is anyone trying to find the real architecture of human cognition, the development of hypothetical architectures at the level of interest here shares plenty with the majority of researchers who are developing cognitive architectures for useful results through models and simulations. We do not need to make that distinction now, though other dimensions of distinction are useful and are considered next.
We will now consider what dimensions there are in the field of this kind of cognitively-oriented study of complex tasks. The neutral term 'works' is in this discussion used to cover what earlier have been called models, theories, architectures or simulations equally. The question is, how many significant ways are there in which works about cognition can differ. If one has an answer to that question, one has at least an idea of the extent of the field one is dealing with, which will help above all when attempting to answer general questions, including those about possible future work.
Firstly, works vary in the degree of dependence or freedom from dependence on a particular domain. The more a work is about a particular domain, say, air traffic control on the approach to a certain airport, the more there may be specific cognitive structures that have been developed for that task. Therefore, a work of this nature in such a domain may not be easy to generalise. On the other hand, a work which was domain-independent would apply to any relevant cognitive activity. A good example would be a theory from cognitive psychology, for instance about long-term and short-term memory.
This first dimension can be extended further, increasing the generality to any abstract way of information processing, and not just human cognition. That includes AI techniques that are not motivated by their correspondence to human cognition. The issue for this paper, with these very general works, is how relevant they are to human error.
Secondly, works vary in their level of specification. This runs from the level of abstract theory, where the specification is only in general terms, to the level of implementation, where there is a fully specified and coded model that can be executed by computer and produce predictions given varying scenarios. The level of specification is not to be confused with the coverage, because one can conceive of a very well-specified theory that aims to predict only one or two phenomena, thus having a restricted coverage.
Thirdly, the issue of coverage comes in two forms. If a work is domain-specific, the question is what proportion of the complex task is modelled. If only a few aspects of a complex task are represented, it may be that certain cognitive mechanisms can be ignored. For example, is only normal operation described, or are interruptions and emergencies also covered? Looking at domain-independent work, the question is what range of cognitive phenomena is represented. A GOMS model, (Card, Moran & Newell 1983) for example, is used for representing expert, error-free performance of a (not too complex) task. If only a few cognitive phenomena are considered, the domain-specific range of application of a work will be limited.
Fourthly, there is correctness, or the correspondence of the work with experimental or practical findings. If a work is highly abstract, it may be difficult to test against empirical results, whereas a practical work of modelling would be expected to predict phenomena that can be compared with phenomena recorded or measured in practice with humans. For a given model, there may be a range of observations for which it is important to be in agreement, and another peripheral range for which, even though the model could make predictions, they are not important.
Fifthly, there is the economy, parsimony or complexity of the work itself, which can be measured in a number of ways: for example, a simulation can be measured in terms of amount of code, while a theory's complexity could be in terms of the number of theoretical constructs used. It is perhaps worth stating that parsimony is only a clear measure of the comparative value of two works when other things, like the coverage and correctness, are the same. In other cases it is just one factor among many.
These five dimensions can be divided into two groups. The last three describe generally desirable qualities, where it is clear what would be better. Works are in general as good as they can be on these dimensions, given the knowledge and resources of the builders. But the first two dimensions appear more as matters of choice. Because of the great difficulty in constructing good, accurate, domain-independent, fully-specified architectures, theories, models and simulations of cognition, researchers may instead choose for pragmatic reasons to make them domain-dependent, or specified only at a high level. If the requirement is specifically for a model of a certain domain of cognitive skill, the value of a domain-independent model is open to question. Equally, if only high-level answers are required to high-level questions, the value of a low-level model is doubtful.
Figure 1: A selection of work on cognition in complex tasks
plotted on the dimensions of domain-dependence and level of specification,
showing potential developments
Focusing on these first two dimensions (the first group) gives us the possibility of drawing a diagram, Fig. 1, on which is displayed the various approaches of different works, mainly in the field of complex tasks. On the left of Fig. 1, there are verbal descriptions of tasks ranging from high-level abstract to low-level detailed ones, that could be detailed enough to be coded in a computing language. These are the domain specific models. Between left and right of Fig. 1 are the cognitive architectures, with the most abstract at the top. The space at the bottom of the centre suggests an ideal situation for a well-specified, executable cognitive architecture able to cover errors and related cognitive phenomena in complex tasks. The right of Fig. 1 is the area of computation that is not restricted to modelling human cognition. At the top, centre and right, the area of highest level, there is philosophy. Across the bottom of the figure, everything is implemented.
This diagram serves not only for the explanation of aspects of the relationship between simulations, models, theories and architectures, but also for the illustration of the question of progress towards better architecture.
Figure 1 allows the consideration of three motivations in the development of models: towards more detailed specification; towards more generality, and towards cognitive relevance. We will now consider these with reference to the labels in the figure.
There are various reasons for wanting a model to be more completely specified. As outlined above, specification of a model at a more detailed level often leads to insights that improve the higher level specification. Conversely, the impossibility of specifying something at a more detailed level can lead to a thorough revision of the previous level of specification. The other motive for detailed specification is computer implementability. An implemented model offers more chance of being tested, and therefore more opportunity for improvement. However, these moves downwards in Fig. 1 are difficult to carry through satisfactorily, and in any case they take much effort.
We can see near the centre of Fig. 1 the progression downwards from psychology theory. Placed to the right of centre, Soar (Newell 1990), and even more, ACT-R (Anderson 1993), result from the effort of taking some results from cognitive psychology and hypothesising and implementing mechanisms (often from AI) that may account for those results. Yet they only deal with certain aspects of cognition. Because ACT-R occupies such an interesting position, which aspects it deals with is analysed in more detail below. There is plenty of room for cognitive architecture with more coverage (the third dimension above, not displayed on the diagram) near ACT-R in the figure.
COSIMO (Cacciabue et al, 1992) implemented ideas about the cognitive processes in complex tasks, working partly from concepts such as those of Rasmussen (collected in Rasmussen (1986)), and partly from the psychological error theory of Reason (e.g. 1990), himself influenced by Rasmussen. COSIMO occupies another interesting position in Fig. 1, and will also be discussed further below.
We may also see Hollnagel's COCOM (1993) as an attempt to move down in the diagram, from the higher-level ideas of Rasmussen, via a recognition that some model was needed of the different ways in which an operator handles information at different times, which Hollnagel calls control modes. It remains a difficult challenge to take the next step down, specifying at a lower level the mechanisms in a satisfactory way. If this could be done, Hollnagel's COCOM model would take its place beside COSIMO, but with a greater coverage of the phenomena.
Models can also be built from careful scrutiny of experimental data. One could see Bainbridge's models as having started like this, building a detailed model of a skill from a verbal protocol and record of system actions. Bainbridge's (1974) study was perhaps too early to benefit from computerised modelling, but at least she did specify her model to a remarkably low level. Amalberti & Deblon (1992), on the other hand, had the benefit of computer tools and produced a detailed simulation of military aircraft operating skill. (The name AIDE, though not appearing in the cited paper, has appeared elsewhere.)
The move, rightwards from the left towards the centre of the diagram, from domain-specific to domain-independent has also been present in the field of complex tasks. In the early history of the field, one can see Rasmussen as making that move. He started out with much observation of power plant operators, and came to theorize at a generalised level about the kinds of cognitive processes going on in them. Rasmussen's success is testified to by the applicability of his ideas to other areas of complex tasks. His main contribution could be seen as introducing a domain-independent view sufficiently firmly based on real-life experiences, so that it was relevant.
Bainbridge, after painstakingly detailing a paper model of a process operator's cognitive skill (Bainbridge 1974), has continued rightwards in the figure, working towards the more general theorizing about a cognitive processing element that is applicable to a wide range of complex task domains (Bainbridge 1993), but as yet without attempting to implement her models as simulations.
The motivation for a rightward move is less immediately apparent and general than for a downward move. Striving for generality may be simply the desire or vision of the research worker or project, or it may be that some results need to be generalised to another domain. Moving to the right does not give the same immediate benefits of testability and confirmation as moving down, and can have disincentives: in the move to the right, many details of a specific domain are no longer relevant, and it may seem that there is little that can be generalised across domains.
One can always attempt a move to the right in Fig. 1 by removing (some of) the domain content from one's model, and proposing the resulting shell (as in an expert system shell) as a generalised cognitive model, ready to be filled with knowledge from a different domain. This will be discussed further below.
Positions far to the right of Fig. 1, on the other hand, are independent of human cognition, and belong to logic and computation in general. Much of the historical development of AI could be located in the space between the right and the centre. The figure includes various examples of attempts to make computational techniques relevant to modelling cognition. GOMS (Card et al. 1983) provides a framework for the hierarchical description of tasks, and its relevance to cognition comes from the fact that humans may also work sometimes with goal hierarchies, but it is also limited by this. The Knowledge Blocks approach of Boy (1991) and followers (e.g. Mathé 1990) is a richer framework including consideration of context and abnormal conditions, and it is currently useful largely for specification of cognitive tasks with abnormal conditions, but not for simulation of errors in cognition, and it is also limited by the hierarchical view.
Newell's Soar and Anderson's ACT-R, mentioned above, both have a heritage from AI, adapting AI techniques more closely to fit selected general features of cognition, and, perhaps more extensively in Anderson's case, to fit accepted results from cognitive psychology. So they both are examples of the move from the right to the centre of Fig. 1.
Sceptic (Cooper & Farringdon 1993) offers a different approach. It is an "executable specification language", which does not claim in itself to model any cognitive processes, but to provide the programming (not cognitive) architecture which supports the implementation of theory about cognition. It does this in two ways. Firstly, by providing a very high-level language, in which prototypes of models may be easily constructed and maintained; and secondly, most importantly in the view of the authors, to keep clear the distinction between theoretical commitment and implementation detail. This is referred to as the "A|B distinction", "A" standing for "Above the line" theory and "B" for "Below the line" implementation detail. Thus Sceptic is really a proposed architecture for cognitive architectures, and this has been demonstrated by the implementation of several examples of cognitive architecture or theory, including a reimplementation of Soar, which turns out to have very much less code and fewer rules than the original (Cooper et al. 1995).
This contrasts with ACT-R, where the basic mechanisms and structures are given, leaving the modeller to fill in just the details of the knowledge (declarative and procedural). We may note the question of where Soar lies with respect to ACT-R and Sceptic, but this will not be addressed here.
In summary, this movement from AI towards cognitive relevance is also well represented, and seems to be a valid approach to making cognitive simulation architectures in the area of interest to this paper.
If a cognitive architecture is to provide the basis for the building of models of cognition, it must be common to the domains that are to be modelled: in other words, it must be more domain-independent. In Fig. 1, this means that architectures will appear to the right of the models that are built from them. Moreover, since an architecture cannot not effectively support models at a lower level of specification than the architecture itself, the level of the architecture in Fig. 1 cannot be above the level of the dependent model (though the architecture could be below).
However, looking at models and architectures at the same level in the diagram reveals potential incompatibility. One of the early complaints made was that theories of psychology were not sufficiently in touch with the realities of complex tasks to provide an appropriate theoretical foundation. And the same problem occurs in other parts of Fig. 1: architectures such as Soar openly admit to missing features that are important for cognition in complex tasks.
If an architecture does not have a certain necessary feature, building a model will necessitate constructing that feature in some domain-specific way. The resulting model may be reasonably complete with respect to its aims, but it will not be generalizable. Its 'shell' (cf. discussion above) will remain as the original architecture, without any additional general features. This explains the observation that domain-specific models far on the left of the diagram can have architectures far on the right - computer architectures that may not deserve the name cognitive.
Taking the example of Amalberti's AIDE, AI techniques were used in the construction of the model, and it is not at all clear from Amalberti & Deblon (1992) how much is domain-independent. The same could be said of other computer-implemented models of complex tasks. What does seem highly plausible is that the more the architecture of a model comes toward the middle of the diagram from the right, in other words the more humanly cognitive it is, the more we can expect models of human cognition made within that architecture to have more domain-independent components, and thus to be more easily generalizable. This goes along with the idea that modelling with a better cognitive architecture would be easier. On the diagram, we can see the two sides potentially coming together.
How can it be decided whether an architecture is rich enough to support a model of errors in complex tasks (or any other requirement)? One way is to examine the claims of the authors. A second approach would be to examine the characteristics of the errors, and the characteristics of the architecture, and attempt to determine from those whether the architecture affords the potential for modelling the feature considered. A third, less reliable, way would be to attempt to make a model following the architecture, and see what the model was capable of. The problem with this third approach is that if a model fails to predict errors satisfactorily, it is not clear whether this is a failing of the architecture, or whether a failing of the way the modelling was done.
The last question raised above about cognitive architectures is difficult and important, and since attempts at cognitive architecture vary so greatly, it cannot be answered in general. Instead, here we examine two particular works in more detail. They are chosen firstly because they have both been specified to the level of implementation, which makes them easier to assess than work that has not been fully specified. Secondly, they are chosen because they represent two sides of an ideal, with opposite directions of potential development. ACTR approaches from the domain independent side, and COSIMO from the domain dependent side. There are also other models of the cognition of process operators and similar humans which could be placed close to COSIMO. Cacciabue (1994) reviews and compares several.
The basis for the discussion here of ACT-R is the book of Anderson (1993) and accompanying material. ACT-R is given extensive discussion here because it is relatively new, and because it is one of the best examples of its class (architectures derived from AI and cognitive science) as candidates for modelling human errors, since it is based extensively on data from cognitive psychology.
The low-level computational architecture of ACT-R is a production system, with the familiar production rules of the form "IF conditions THEN actions". Newell's (1990) Soar is also based on a production system, which forms part of a long history of AI and cognitive science work, particularly in America.
Next, three essential theoretical commitments form the basis of the ACT-R architecture. These are clearly theoretical rather than implementation detail, and thus "above the line" in Cooper's (1995) sense.
Anderson writes that a theory of skill acquisition is at the heart of the book (p.143). The theory is stated as follows.
- The knowledge underlying a skill begins in an initial declarative form (an elaborated example), which must be interpreted (problem solving by analogy) to produce performance.
- As a function of its interpretative execution, this skill becomes compiled into a production-rule form.
- With practice, individual production rules acquire strength and become more attuned to the circumstances in which they apply.
- Learning complex skills can be decomposed into the learning functions associated with individual production rules.
This emphasis on skill acquisition, rather than complex skill use, is significant and important. The implication is that when considering selection of production rules in operation (through the process of conflict resolution), the kind of selection that will be of importance is that found during the learning of a task, between different plausible actions that may bring the subject nearer to the goal. This is the kind of situation that has been considered extensively in AI, where a subject is attempting a puzzle or game whose solution strategy is not known. The concern of ACT-R will naturally decrease at the point where an effective strategy has been learned. A corollary of this is that ACT-R is less intended to account for the kinds of phenomena observed in overlearned situations, commonly studied in the observation of complex tasks, and in particular, errors at that much later stage of expertise. In ACT-R, when a task is performed and knowledge is used, productions are selected on the basis of a number of factors, including the strength, or activation, of the procedural and declarative elements of knowledge. The kind of options being chosen amongst are not typically the same as the kind of options seen in overlearned complex tasks performed under conditions of uncertainty, risk, time pressure, and mixed, competing goals.
In terms of Rasmussen's levels, one could perhaps see Anderson as giving a theory of how an eventual cognitive skill changes from Knowledge-based to Rule-based. How much is explained of the onward evolution of a skill to what Rasmussen calls Skill-based is debatable. Anderson's approach to this is by the idea of tuning of the productions and declarative knowledge elements. Production tuning is a change in the 'strengths' of production rules, which in turn, like the activation of declarative knowledge, affect the selection of production rules at the time of execution.
Anderson gives some clear leads on what errors can be modelled within ACT-R. Errors of omission can be explained either in terms of missing or buggy production rules, or in terms of a given production rule not firing due to problems with conflict resolution and production selection; but given the satisficing approach, errors of commission are not currently modelled. However, it is suggested that a partial matching mechanism would be able to produce such errors of commission.
After reading what Anderson writes explicitly, the next place to look for sources of error is in the mechanisms of ACT-R themselves. Looking at declarative memory suggests error potential from incorrect chunks. The question, not addressed here, would then be how they could arise.
The analogical mechanism could also throw up errors. It is, however, difficult to see what kinds of error this can lead to, given the goal-oriented basis of ACT-R. Analogy is seen as a potential extra way of achieving the goal, and if it does not work, either a solution will not be found (covered above) or solution will be delayed. Without a basis of multiple conflicting goals, the manifest error types specifically due to failure of the analogy mechanism are unclear.
Other learning mechanisms are based on feedback from successful operation, and for them to cause errors, the feedback would have to be misleading, in the sense that an erroneous outcome would have to be judged successful. There is no obvious way of modelling this kind of event within ACT-R.
After considering the mechanisms of the architecture, and the possible errors that can arise from them, the next stage in the evaluation of the error-modelling potential is to consider a range of errors that are evident in the kinds of tasks under consideration, and to see if, and how, ACT-R could possibly account for those errors. It is not sufficient to see what mechanisms are not present in ACT-R, suggesting that errors which can be accounted for by those mechanisms are not explained, because ACT-R may have a different explanation of the same errors.
Reason (1990) gives a detailed classification of errors (failure modes), referred to as GEMS (generic error modelling system) and we may look at least at the general headings to guide the likely common types of error to be explained. Reason's broad categories, inspired by Rasmussen, are failure modes at the skill-based, the rule-based, and the knowledge-based levels. At the skill-based level the errors are connected with attention. Attention does not explicitly feature in ACT-R, since the problems that are considered there are not ones where attention and perception are critical. As a consequence, errors due to attention problems are not modelled in ACT-R. Reason's rule-based level is one at which one would expect ACT-R to have more to say, since its representation is in terms of production rules, and indeed many of Reason's subcategories can be related to mechanisms in ACT-R. However, at least one, "informational overload", is not modelled within ACT-R. At the knowledge-based level it becomes clearer that there are many relevant human failure modes that are not addressed by ACT-R. Reason gives a number of subcategories such as workspace limitations, confirmation bias, overconfidence and problems with complexity. These appear not to be modellable in ACT-R - for instance, there is no explicit limitation on working memory usage.
One can also consider other classes of error suggested by other workers. An easily recognised category would be errors caused by time pressure, for example. ACT-R does have time considerations in the selection of productions, so it is conceivable that ACT-R could be made to model time-pressure errors, but for this to be effective, there would have to be partial matching of production conditions. Extending from this, Woods et al. (1994) provide a very useful list of error categories in complex tasks, and discuss particular cases, such as mode error, in depth. It is difficult to see how ACT-R might account for mode errors.
A full analysis of the error-modelling potential of ACT-R would need considerably more study, and would merit a paper to itself. This would be appropriate if a researcher was seriously considering using ACT-R to model these errors. What has been presented here demonstrates the general approach, and may be outlined in a table as below. This is enough to suggest at least that at present, ACT-R is not particularly closely-adapted to modelling errors in overlearned complex tasks.
ACT-R mechanism Error type
Procedural production rules Omission: missing or "buggy"
rule
Declarative Chunks Erroneous declarative
knowledge
Conflict resolution suboptimal rule selection
Analogy ?
Production creation ?
Production tuning ?
(could be done by partial some errors of commission
matching)
- Several skill-based errors
- Many knowledge-based errors
Table 1: Some mechanisms in ACT-R compared with some error types
Though ACT-R does not explicitly contain mechanisms covering all the relevant types of error, that fact does not prevent a modeller from proposing or introducing specific production rules or general declarative knowledge that could in some way model them. The difficulty here is that when something of this importance is left to the ingenuity of the modeller, the architecture is offering no help in constraining the model to lie within the bounds of psychological plausibility. Furthermore, the model would be difficult to generalise, and since ACT-R (unlike Sceptic) does not support a clear distinction between theory and implementation detail, it may be inappropriate to expect a model builder to extend cognitive theory at the same time as modelling a cognitive skill in a particular domain.
The above considerations taken together suggest that, to develop ACT-R into an architecture for modelling errors in complex tasks, the approach of choice would not be to work within its current framework. It is more difficult to see how its potential could be improved. The interest in this question comes since it is one of the nearest architectures to what is needed.
Some of the problems identified above come from the fact that ACT-R works with a goal hierarchy and a goal stack. Anderson does not discuss any empirical evidence there may be that humans find it difficult to keep track of a deep goal stack; but it is generally observable that people do find this difficult. So one conceivable development would be for ACT-R to free itself from its rigidly hierarchical representation of goals. This is just an example, and of course there are many other possible developments.
In contrast to ACT-R, COSIMO (Cacciabue et al, 1992) comes from the cognitive engineering tradition where the models are based on experience and collective wisdom of the realities of humans performing complex tasks. This tradition has recognised that it is quite difficult enough to make satisfactory models of stable complex skill; and so the question of modelling the acquisition and development of cognitive skills has scarcely been addressed. COSIMO does not claim to be a cognitive architecture, but a cognitive simulation model, originally of decision making and behaviour in accident management of complex plants, and more recently for parts of civil aviation piloting tasks. Nevertheless, what is described in the cited paper is largely an abstraction from the model. It is this abstraction which is examined as the cognitive architecture of COSIMO here.
Since its development involved collaboration with Reason, COSIMO shares much common ground with his theory of cognitive underspecification (Reason 1990). This follows on from the GEMS analysis referred to above, and Reason states it thus: "When cognitive operations are underspecified, they tend to default to contextually appropriate, high-frequency responses." Thus, two main cognitive mechanisms were proposed that could be held responsible for cognitive errors both in Reason's work and in COSIMO: similarity matching and frequency gambling.
These two mechanisms still did not constrain COSIMO a great deal, and they needed further specification for implementation. COSIMO made a pragmatic choice of a blackboard architecture as the implementation approach, and three reasons were given why this was chosen:
"1) it supports the adaptive behavior of reasoning of an operator; 2) it supports an explicit representation of mechanisms that enables the dynamic revision of its behavior according to new information that continuously change the problem scenario; 3) it allows an incremental and opportunistic decision making development."
While this choice is reasonable, it was not claimed that no other architecture would support the same features, and the blackboard architecture could be seen as an implementation detail, rather than a central part of COSIMO's proposed theory. In any case, the blackboard architecture does not strongly constrain modelling, and much still relies both on the elicitation of knowledge from the domain practitioner, and on the skill of the modeller in representing that elicited knowledge as information structures that are runnable by COSIMO. It is clear that COSIMO is only a partial model, in the sense that there are several phenomena that it does not address: limitations for inferential, temporal and analogical reasoning, for example, are mentioned by the authors.
Cacciabue et al. (1992) demonstrate examples of particular domain-specific error phenomena obtainable with COSIMO. If one were interested in further analysis of this, one could draw up a table similar to the one for ACT-R, comparing mechanisms with error types. COSIMO makes no attempt to account for a complete taxonomy of error types. Interestingly, this is a similar position to the one arrived at by Reason, who despite having produced a detailed classification of error types, did not systematically attempt to explain each one in terms of his "fallible machine" design, which is based on similarity matching and frequency gambling.
Though COSIMO appears to approach development from the opposite position to ACT-R, we are left with an evaluation that is surprisingly similar. The mechanisms within COSIMO have not been used systematically to explain and model a complete range of error types observed in complex tasks. Instead, models of errors in COSIMO have relied on domain-specific factors being modelled to produce the observed errors, and this would be difficult to generalise. Both architectures need development: ACT-R to be more closely relevant to cognition by modelling more mechanisms; and COSIMO by taking cognitive errors away from domain-specific modelling, towards general domain-independent mechanisms.
What, then, are the possible approaches to developing cognitive architecture? Four approaches are given here: the incremental approach, which starts from examples of what there is and identifies possible incremental improvements (anywhere in Fig. 1); the approach from the real world, which proceeds from modelling real world complex tasks towards greater generalizability; the approach from theory, developing models of cognitive processes; and a balanced approach, which incorporates the previous two approaches.
This approach is similar to trial-and-error problem solving. A researcher identifies a set of previous works, evaluates them in some way, and proposes improvements or directions for improvement. This is a very general approach which has in part been followed above, with reference to ACT-R and COSIMO. Another paper that follows this approach is Cacciabue (1994). He chooses seven requirements, or criteria for comparison, of existing cognitive models, and the resultant evaluation matrix shows the directions of potential improvement of each model. Cacciabue's criteria are: having a computational model; modelling intentions and goals; sensory-motor response; rule based processes; contextual control; cyclic processes; and unexpected situations. More generally, any aspects of existing models, architectures and theories may be compared. If the good characteristics of various models can not only be evaluated, but also integrated, this could be a promising approach.
The same paper by Cacciabue discusses a distinction between micro- and macro-cognition. Micro-cognition focuses on the mechanisms of cognition, and can be approximately identified with the right side of Fig. 1 above. Macro-cognition is about cognition in realistic (complex) tasks, and models of these tasks roughly occupy the left side of Fig. 1. The study of real, as opposed to psychology laboratory, tasks has been a subject of general discussion at least since Rasmussen, and one of the more recent, and fuller discussions relevant to errors in complex tasks is by Woods et al. (1994).
Cacciabue claims that the simulation of micro-cognition and the simulation of macro-cognition are radically different. He just intended to point out the fact that the origins and orientation of those works are different, though Fig. 1 suggests that directions and goals of the two may be convergent. It is agreed that in the ideal case, models of micro- and macro-cognition would converge. The developments from the two sides of this distinction have already been identified above, as the motivation towards generality, and the motivation towards cognitive relevance. A little will be said on each, to summarize and add to what was discussed above.
Approaches from the real world start with domain-specific knowledge and models. This may be modelled directly, as by Amalberti & Deblon (1992) for the case of military aircraft pilots. A similar approach is being undertaken by Amat (1995), who is aiming to integrate some more general insights (including some from COSIMO and COCOM) about cognitive processes into her model, and should therefore end up to the right of AIDE in Fig. 1. Testing out a hypothetical general mechanism in a simulation based on one domain is a useful start to exploring the generality of that mechanism in practice.
Another variant is to start with already generalised, but not implemented, findings on cognition and error. This ranges from the well-established work of Rasmussen to newer contributions such as that of Klein et al. (1993). Though there are conflicting opinions on the feasibility of formalizing and implementing the Naturalistic Decision-Making work, proceeding from generalized discussion of real-world complex task cognitive phenomena is still a plausible way to approach the development of better cognitive architecture.
This approach, instead of starting off with a domain model, starts with concepts of more general-purpose computational mechanisms, and works towards relevance firstly to human cognition, and eventually to particular domains where human cognition is used. That may include errors in complex tasks. The method is often used to build models of cognitive processes, and then to try those out on cognitive tasks, to see how much can be explained in terms of the cognitive processes modelled. When a natural phenomenon occurs that is not able to be explained in terms of the mechanisms implemented, the challenge is to extend the cognitive mechanisms to account for these other phenomena.
Of course, the direction of this approach is determined by which natural phenomena are taken into account. Reason (1990), for example, while discussing errors in complex tasks extensively, reports the modelling of tasks involving remembering the names of American presidents, which gave some feedback about the proposed mechanisms of similarity matching and frequency gambling, but was not very close to his important discussion of latent errors in complex systems.
A focus on affect leads to the approach taken by Sloman's group in Birmingham, England, working on architectures for modelling cognition and affect. A recent paper from this group is by Wright et al. (1995). Many aspects of affect are not directly relevant to complex tasks, but if one considers time pressure and stress, modelling affect may be useful, or there may be a synergy between modelling affect and modelling some other aspects of complex tasks.
There is evidence that ACT-R is potentially open to development by way of increasing relevance. A recent paper from the ACT group (Lee et al. (1995)) starts to investigate the relevance of ACT-R modelling to an Air Traffic Controller task, which is a typical example of the kind of complex, real-time task of interest to other authors referenced in this paper.
The final approach to developing cognitive architecture balances the previous two. Implementations of highly domain-specific models have computer architectures that tend not to be in any way cognitive. The more cognitive mechanism is included in the architecture, the less has to be modelled for each individual domain. The ideal position is where the cognitive architecture is rich enough that the domain knowledge elicitation and representation does not waste effort reproducing mechanisms - reinventing the wheel, one could say. From the other point of view (left of Fig. 1), one would say that the ideal position is that the mechanisms modelled give the maximum degree of generalizability and reusability. In the end, it does not matter which side leads the way, because both directions are revealed as proceeding hand in hand. In terms of Fig. 1, the aim is for progressive convergence, with ever greater coverage (never complete in any foreseeable future), at the bottom centre of the figure.
If the quest for better cognitive architecture is taken seriously, there is likely to be a demand for a meta-architecture, better than Prolog or a production system or a blackboard architecture, which will help in the specification of the theoretical and implementational parts of emerging architecture, partly by giving appropriate restrictions to maintain psychological plausibility, and partly by being integrated within a helpful development environment. Sceptic (Cooper & Farringdon 1993) represents perhaps the first candidate for this role of meta-architecture.
Most of the detailed study of human error in complex tasks has been done since about 1980 (Woods et al. 1994). The study of computational approaches to cognition has been active in AI and cognitive science for longer, but there is little history of overlap between these areas. Nevertheless, considering the number of recent suggestions and attempts to model errors attributed to humans, and the potential usefulness of such models, the subject of cognitive architecture to support those models deserves a substantial place. Architecture to support models of individual cognition is also a subset of architecture for system cognition.
The main conclusion of this paper is that the cognitive architectures that are now available are not yet able to support modelling of errors in complex tasks in a generic way, because of lack of attention given to detailed modelling of hypothetical cognitive mechanisms that may be responsible at once for good performance and for errors. However, building from the existing architectures, and also from real-world studies, makes sense and seems in principle possible.
The role of this paper has been to cover groundwork rather than to offer specific solutions: some indications of possible directions and applications are given in other papers by the present author (Grant 1994, 1995a, 1995b).
Thanks are due to Anne-Laure Amat for suggesting the two dimensions of Fig. 1, and for giving very useful comments on earlier drafts, also to Gordon Baxter for comments.
| © 1995 11 | Home page | Publications | Paper frame | |
| Bibliographics | authorship | abstract | contents | references |